안녕하세요
AX전환팀 우디입니다.
앞서 사과박 물질흐름분석에서 언급한 것 처럼, 저희팀은 ByOrbit 을 개발함에 있어서, 부산물의 데이터베이스를 정립하고 있습니다. 이 과정에서 데이터를 수집하고, 재정립하며 자체 Database 를 구축하는 부분에 힘쓰고 있습니다. 이번에는 내부에서 사용하고 있는 농산부산물 분석 Agent 에 대해서 소개해드리고자 합니다.
부산물 원료화에 대한 분석이 왜 필요할까?
원물에 대한 부분은 이미 많은 데이터들이 축적되어있습니다. 하지만 부산물의 경우에는 그 데이터를 찾기가 너무 어려운 상태입니다. 부산물이 우리에게 원료로서의 가능성이 없기 때문일까요? 저희 팀이 리서치를 해온 결과는 그 반대였습니다. 이미 우리가 알게 모르게 사용하고 있는 많은 제품들이 실제로는 부산물에서 시작된 것들이 많이 있었습니다. 최근 석유 이슈로 표면화되고 있는 '나프타' 역시 석유 정제시에 나오는 고분자 탄소화합물 입니다. 그리고 단백질 쉐이크로 많이 드시는 '유청' 역시 치즈를 만드는 동안 응유(우유 고형분)를 분리한 후 남은 액체로 50년 전만 해도 치즈 제조과정에서 남은 유청은 그대로 폐기됐으나, 지금은 활용해 음식물 쓰레기를 줄이는 데 기여하고 있습니다. 그 외에도 많은 원료들이 있습니다.
그래서 우리는 부산물 원료화에 따라 성분을 데이터베이스로 구축하는 작업을 하고 있습니다. 꼭 소재화가 아니더라도, 그 과정을 통해서 버려지는 농식품부산물들이 절감되는 것을 넘어서 우리 삶에 필요한 원료로서 부가가치를 가지게 된다면 그것이 우리가 나아갈 미래라고 생각하기 때문입니다.
하지만 부산물 원료화에 대한 분석데이터를 모으고, 분석하는 과정이 쉬운일은 아닌 상태입니다. 그래서 우리는 이 데이터들을 처음부터 모아서 표준화될 수 있는 분석 AI Agent를 구축하고자 작업을 하고 있습니다. 아직은 데이터가 부족하기 때문에 그 정확도에 대해서 확신할 수 없습니다. 하지만 계속해서 쌓아나간다면 앞으로는 엄청난 시간을 절감할 수 있을 것으로 기대하고 있습니다.
원물 데이터는 국가표준식품성분을 통해 구축
원물데이터는 이미 국가표준식품성분으로 DB가 잘 만들어져있습니다. 원물데이터를 수집하는 것을 어렵지 않았습니다. 각 원물별로 기초 성분을 DB로 만들고, 자체적으로 정립한 분석기준에 따라 성분분석 처리가 가능하도록 구축했습니다. 이 과정을 통해 모여진 데이터들은 저희의 분석기준에 따라 간이진단과 정밀 분석이 가능하도록 만들어졌습니다. 이 부분 역시 실제 성분데이터 내용과 차이를 좁혀나가는 것이 하나의 미션으로 남아있습니다. 하지만 최소한의 기준 분석에 대해서는 어느 정도 신뢰도를 가진 모습을 갖춘 상태입니다.
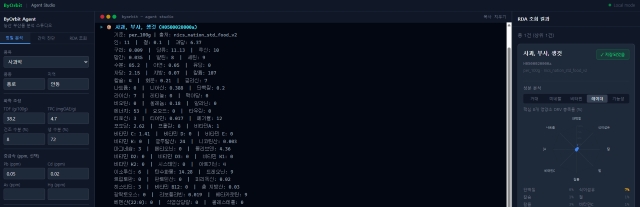
검증 단계
저희는 기본 원물데이터를 토대로 부산물의 상태 데이터와 전처리 이후의 데이터를 수집하고 검증하는 단계에 있습니다. 기초적으로 저희가 가지고 있었던 소재화하고 제품화 했던 것들을 먼저 데이터로 검증하고 있습니다. 그리고 이 프로젝트가 궤도위로 올라왔을 때는 간이 진단으로도 부산물의 원료화 가치를 예측할 수 있도록 하는 것을 목표로 하고 있습니다. 수요 정의 및 적합도에 대한 평가를 진행하고, 리포트를 제공하고자 합니다.
이 과정에서는 제품 목표, 필요기능,허용 조건에 대해 적합도를 파악하고, Sepc Sheet 와 COA구조, 공정 등에 대한 샘플작업과 내부 벤치테스트. 그리고 PoC 및 파일런 생산이 가능하도록 하여 일관성 검증을 진행하고자 준비중입니다.
또한 중요한 과정이 이런 검증과정을 거치면서도 규제검토가 함께 들어가게됩니다. 이 부분은 국내,국외 루트를 모두 파악하고, 고부가가치 원료로서의 가치가 확정된다면 빠르게 그 부분까지 해소할 수 있도록 함께 탐색합니다.
이 프로젝트는 저희 내부적으로도 매우 중요한 검증프로젝트입니다. 연구소와 계속해서 소통하며, 완성도를 높여나가고 있습니다. 앞으로도 저희는 데이터 기반 원료화를 위해 필요한 기준을 만들어나가고자 합니다. 2025년도부터 성균관대학교와 함께 ByOrbit 프로젝트를 함께 산학협력하고있으며, 올해부터는 본격적으로 부산물 DB구축을 해나가고 있습니다.
감사합니다.
